Summary
Summary
The Open University, in partnership with Forest Research and Treeconomics, has recognised the need to better educate people about the role of trees in the community, and the necessity of involving citizens in their protection and conservation.
In June 2013, the partnership launched Treezilla: a free, online multi-purpose platform designed to support tree-related science projects as part of the Open Science Laboratory in the Science Faculty of the Open University.
Status
This project began in June 2013 and is ongoing.
Funders and partners
This work is part-funded by the Forestry Commission, in partnership with the Open University and Treeconomics.
Intelligent Tree Data Validation
This page describes the development of an intelligent validation system for crowd-sourced urban tree data.
Rationale
A shortage of easy-to-use, reliable data about trees in towns and cities is preventing a knowledge-based approach to optimising benefits from trees and reducing conflicts between local authorities, tree contractors, and members of the public.
Cuts to local authority budgets and increased workloads are making it increasingly difficult for local authorities to manage and monitor their urban trees. The scale of the task means that authorities and contractors do not always fully understand the way that citizens assign value to the trees in the surrounding environment.
To tackle some of these problems the COMMUNITREE project aimed to enable members of the public to share ownership and responsibility for care of urban trees, in particular by collecting and recording urban tree data that would be freely available to local authorities.
Crowd-sourced data must be reliable if it is to be used for management of urban forests. Citizen scientists must be supported in learning tree identification and surveying skills. Potentially erroneous data entries must be highlighted to the user as they are entered into a database to provide an opportunity for the data to be double-checked or re-measured.
This work is linked to the Individual Tree Data Standard, which has been designed to help tackle the difficulties associated with sharing tree data between organisations.
Vision
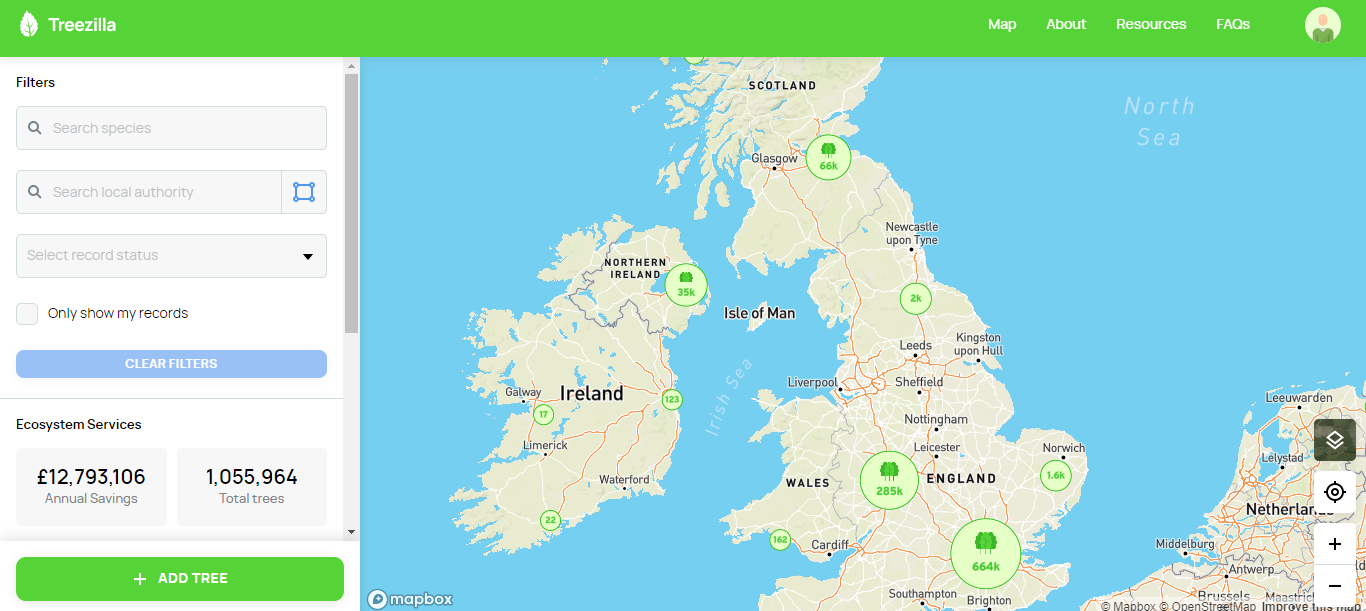
This project aims to create a system for validating tree data at the point of input, to improve the accuracy of the data and the skills and knowledge of citizen science tree surveyors. It has been designed for the UK’s and world’s largest open source urban tree map Treezilla.
Citizen scientists will be inspired as they are supported in building their skills in tree identification using published guides, quizzes and the validation feedback mechanisms. This ongoing education of contributors will increase their reputational status, improve the data quality in the dataset, and achieve a world first.
Approach
The system is based on a validation rule set which can be applied to data collection apps, data collection web forms, bulk upload of tree data, and existing datasets in Treezilla.
The rules use simple allometric equations such as the relationship between trunk diameter at breast height (DBH) and total tree height. These rules enable the data collection platform to flag potentially erroneous data (e.g. tree height is too tall for DBH).
Existing data can be filtered based on these rules, and excluded from analysis or modelling studies. Newly recorded data can be double-checked against paper forms or re-measured on site.
Some tree species are difficult to identify and require expert knowledge and years of experience. Species name feedback will be provided to the user to highlight species that are difficult to identify, such as willows and oaks. The user has the option of changing the entry to genus level, double-checking their identification, or keeping their entry if they are an expert user.
Surveyors are awarded a reputation based on the Open University’s iSpot website.
Research Objectives
- Create intelligent, live data validation system for use during data entry
- Encourage public participation in validating new and existing tree data
- Improve accuracy of citizen science tree data to make it recyclable for many uses
- Enhance skills and understanding of tree data collectors and users
Contact
Research Objectives
The objective is to create an online map of all the trees in the UK that can be used for 5 types of activity: Education, Outreach, Research, Inventory and Biological Surveillance.
General Content
Development
In February 2016, the ViTAL project received NERC funding to expand the functionality and coverage of Treezilla.
Through the COMMUNITREE project, funded by the Geospatial Commission, a new app and web map were developed to make it easier for contributors to add trees to Treezilla. Intelligent Tree Data Validation was developed to check tree data as it is entered in Treezilla. This is a world first in tree data collection.
The Individual Tree Data Standard will increase the interoperability of tree data, enabling it to be collected once and used many times.
Funding & Partners
- Forestry Commission
- Open University
- Treeconomics
- Natural Environment Research Council
- Geospatial Commission